Linux编程 基础
我们学习Linux的主要目的就是为了在让我们所写的代码可以在Linux环境下稳定运行,因为作为一个服务端程序员,我们将来所接触的服务器的系统内核全部都为Linux,也就是说我们所写的所有代码都要求在Linux服务器上依然可以稳定运行,这是作为服务端程序员的基本素养。因此Linux环境下的编程也是我们必须要学习的。
第1节
Linux编程准备材料
我们将来并不是直接在服务器上对Linux服务器进行编程,更多的是用远程链接的方式来操作服务器,因此作为远程链接的桥梁有一款软件是我们今后会经常使用的,也是之前我所提过的Xshell。其实在Linux系统内核外壳有一门独到的脚本编程语言,我们利用这款脚本语言来控制Linux,这款语言就叫shell。我们之前所说的Linux基本命令其实就是在利用shell脚本语言来控制Linux系统。而在这里所说的Xshell这么一款模拟Linux终端的模拟软件,在Xshell里链接到我们的Linux系统后的操作就与直接在Linux终端里的操作几乎完全一样了(实际上还是有一些区别)。因此我们之后的所有操作都会利用Xshell来远程控制我们的虚拟机。因此在Linux编程中Xshell是必不可少的。
Xshell下载地址:https://gitee.com/HGtz2222/xshell_install_package/raw/master/Xshell-6.0.0082p.exe
将Xshell连接到Linux
1、打开Linux虚拟机和Xshell。我们要将Linux连接到Xshell首先当然肯定是要先打开我们的虚拟机啦,当然Xshell也要打开
2、在Linux终端输入ifconfig指令,然后在下图红框处找到自己的ip地址。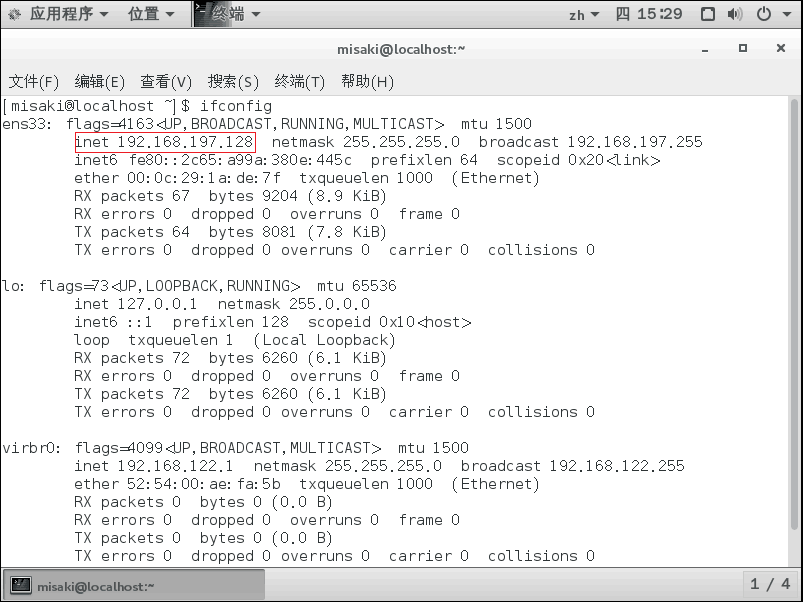
然后在Xshell中输入如下图的命令。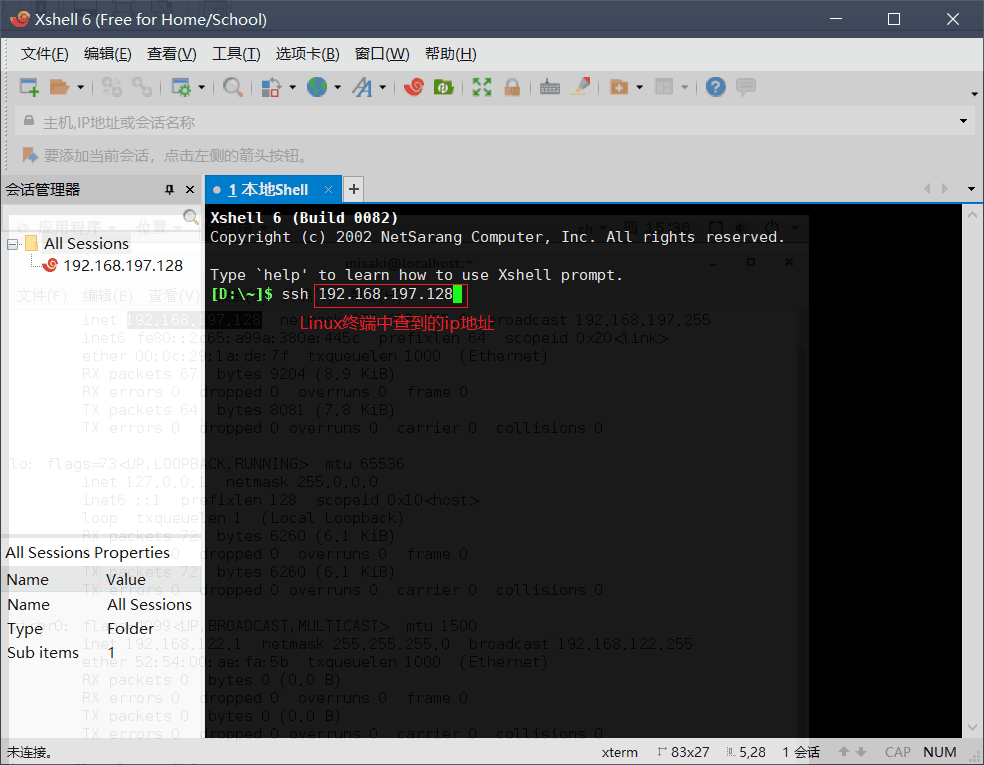
之后按要求输入Linux中的用户名及密码即可连接上虚拟机。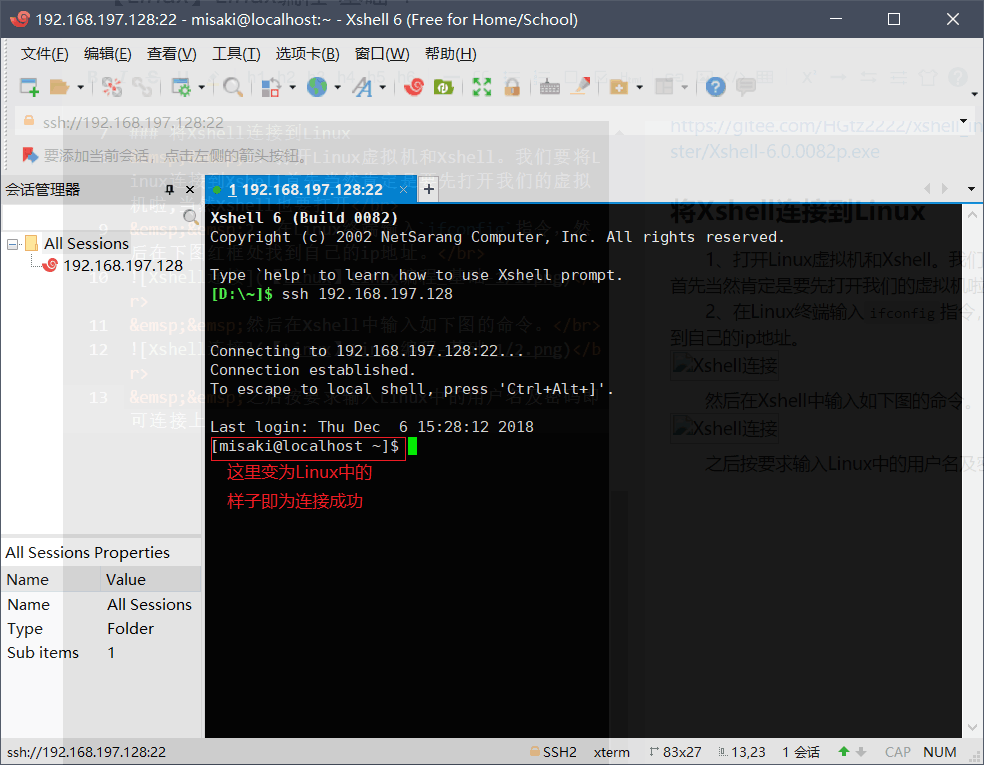
连接上之后的操作都和Linux终端中的一致了。同时Xshell比Linux的终端好看了不止一点,可以改变界面透明度和背景,使用起来心情舒畅多了。
如何在Linux中编程
正如我们之前在Windows中使用的vs2017这个ide一样,在Windows中我们大多使用类如这样方便的集成式ide来进行编程,ide将我们编写程序所需要用到的工具进行整合,合为一体供我们使用,十分方便快捷。
而在Linux中不同于Windows的是,Linux这类操作系统更崇尚的是利用简而精的软件而并非Windows使用所崇尚的这种一站集成式的软件,因此在Linux中编程我们并不会接触到类似于vs2017这样的集成式的开发环境,而是将其打散成多个小软件分别使用。这样的方式是类Windows操作系统与类Unix操作系统关键性的区别。
那么在vs2017这个继承开发环境中都包含了哪些基本的功能供我们使用呢?可以大致分为以下四种,并且我们在Linux中都找到了对应的软件来代替vs2017中这一功能,我也一并将其列出来。
1、代码编辑器 —— vim。
2、编译器 —— gcc。
3、调试器 —— gdb。
4、项目组织 —— makefile。
以上这四款基本软件我们今后在Linux编程中会经常使用,可以说只要是在Linux下编程就必定会用到这四款软件。那么我们怎么在Linux下找到这四款软件呢?
yum使用
在Linux中内置了一个类似于应用商店的东西,我们称之为包管理器。在这个应用商店中我们可以找到一些我们常用的包,来提供给我们的Linux一些新的扩展功能。接下来我会以在yum下载rzsz这个软件包为例讲解如何使用yum。以下流程均需虚拟机联网。
1、我们先利用yum来搜索rzsz的软件包。输入yum list | grep rzsz命令,稍等即可出现搜索结果。如果过长时间未出现结果可取消重试或检查网络连接后重试。(ctrl+c取消命令)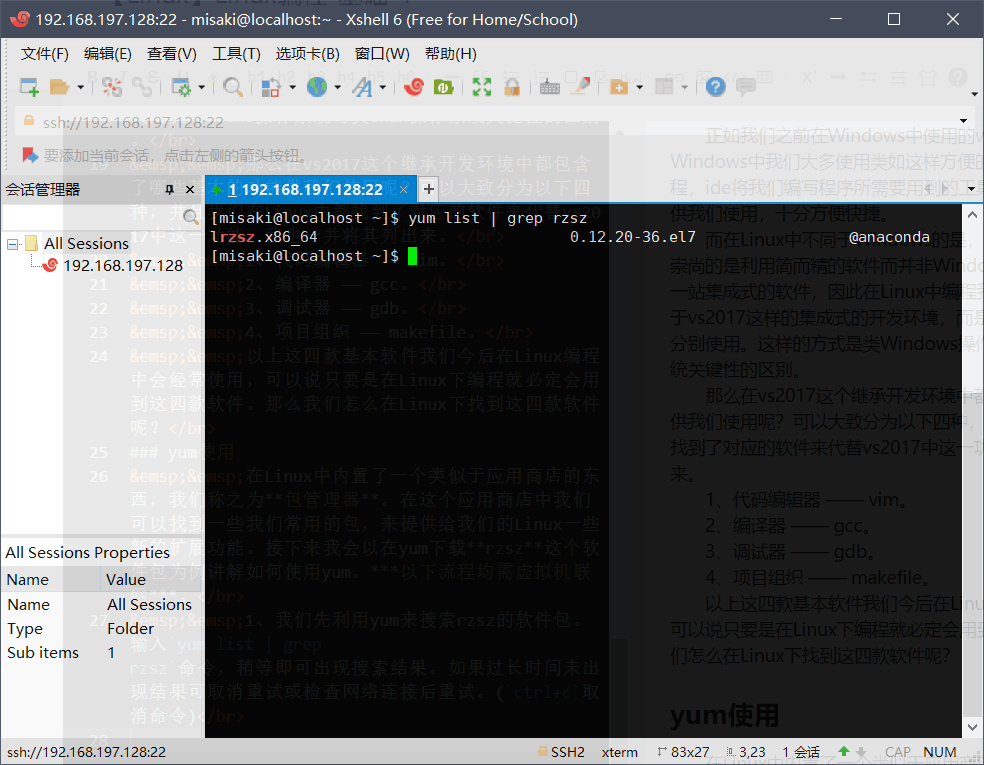
2、切换到root管理员下载安装rzsz既可。确保自己在root管理员权限下输入yum install 包名即可自动安装,其中包名为我们刚刚搜索出来的软件包的名称。
注意:在Linux下安装删除软件均需切换到root管理员才可执行。
(输入su命令后输入root密码后即可切换为root管理员。)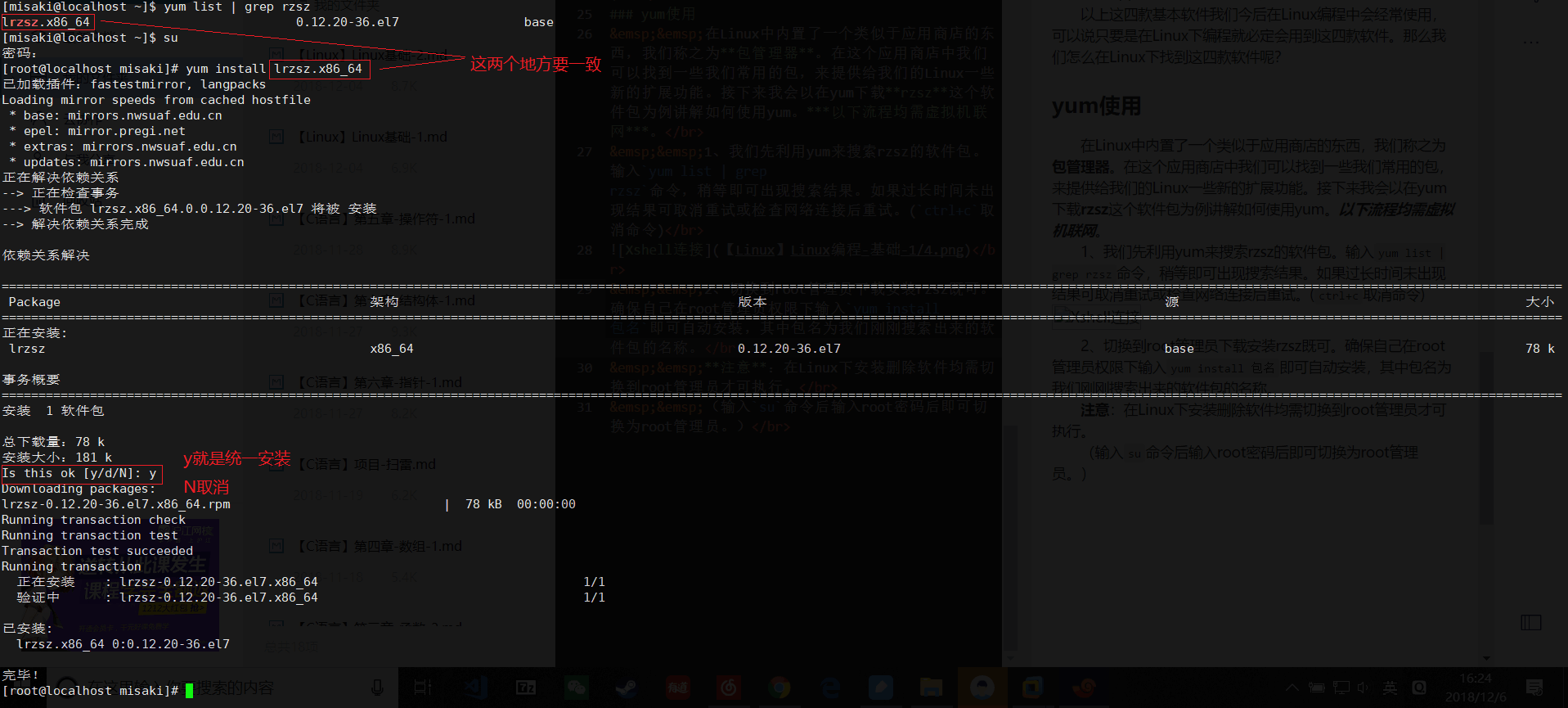
之后我们的rzsz就安装成功了,如果需要删除这个包,则也需要在root管理员权限下,输入yum erase 包名即可。当操作结束后最好退出root权限(输入exit即可退出)。毕竟还是用普通用户比较安全。
虽说我们安装好了rzsz但是这个包到底有什么用处呢?大致作用可以解释为让Windows和Linux两个系统上的文件可以自由快速传输,如果没有这个软件包纯粹利用FTP进行文件传输有着极高的延迟,而且不够方便,而有了rzsz这可以大大改善这一点,是我们将来工作的必备软件包之一。
之后的准备
在介绍完yum的使用后,我们平时使用的很多软件包都可以直接从yum上进行下载,但也并非所有东西yum里都有。
但是在Linux编程上我们要经常使用vim、gcc、gdb、makefile这四款软件,但是好消息是这四款软件有的在Linux上已经提前安装好了,我们直接使用即可。关于这四款软件的具体使用会在Linux编程的其他章节继续介绍。